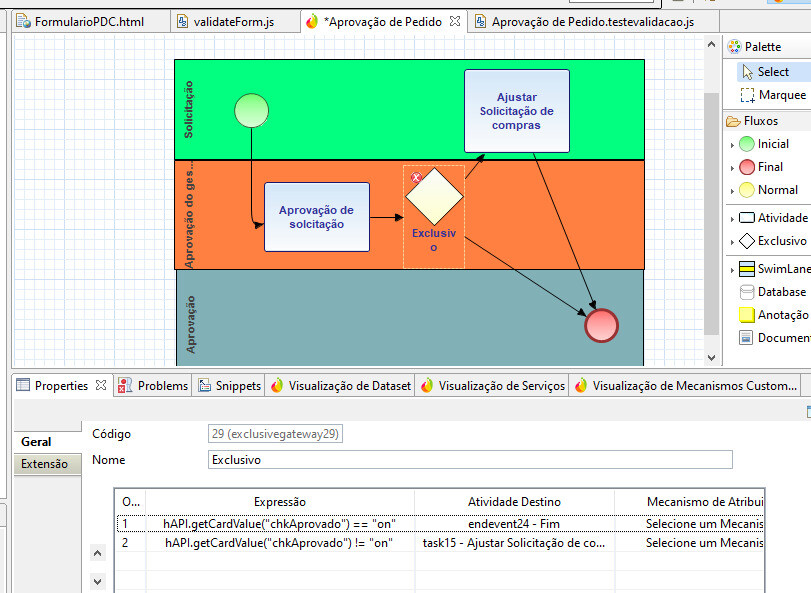
Galera tô com uma dúvida e gostaria de ouvir sugestões
Tenho um processo onde em determinado momento preciso consultar um dataset, esse dataset pode retornar algo ou vazio.
Se retornar vazio, deverá seguir para caminho A, se retornar algo, deverá seguir para caminho B.
O q vc sugerem. Uso um serviço para consultar e se der vazio retorno throw e mando para caminho A ou se achar retorno True e mando para o caminho B?
Ou então, um script condicional para gravar um campo e retorno True para as duas opções e uso um gateway pra consultar esse campo.
Pergunto isso, pq nao é mais recomendado usar o hapi.setautomaticdecision
O que recomendariam?
Wasley bom dia.
Vou te responder o que eu faria, não por ser a melhor opção, mas porque é a que tenho maior familiaridade.
Eu gravaria um campo e utilizaria um “gateway”. A vantagem de gravar um campo é que você saberia que naquele momento da decisão no processo, o retorno do seu “dataset” tinha aquela informação específica. Não sei como está estruturado seu processo, mas se de repente a informação de retorno do seu “dataset” em um outro momento fosse modificada, você teria um, vamos dizer assim, histórico do que estava no momento da decisão do caminho A ou caminho B.
Não sei se consegui ser claro na minha explicação.
Espero ter de alguma forma ajudado.
2 curtidas
Wasley, bom dia, ambas as soluções atendem perfeitamente, é necessário uma atividade automática. Acho que para definir qual dos componentes deve utilizar você deve responder a seguinte pergunta: a informação que vem do dataset é referente ao entendimento do processo (diagrama)? Se sim, acredito que deve utilizar um gateway, ou seja, se estamos falando de tomar decisão o componente mais indicado é o gateway já que ele confere esse sentido ao processo. Se o intuito é processar alguma informação, chamar integrações, alterar algum registro ou qualquer outra coisa que seja fora do processo, aí deve utilizar uma atividade de serviço. É sempre necessário lembrar que ao desenvolver um fluxo não estamos simplesmente fazendo algo que funcione, o diagrama também precisa conferir sentido, lógica e intuitividade ao processo, já que essa é a proposta do BPMN.
Espero ter contribuído, Wasley!
2 curtidas
Essa ideia do @Cassius de gravar em um campo pra ver o histórico de modificações do retorno do dataset é muito válida. Mas se você estiver usando essa verificação somente uma vez durante o workflow eu acho desnecessário. Eu já utilizei essa solução várias vezes. No beforeTaskSave antes do gateway eu fazia o cálculo e salvava em um campo qual a atividade de destino que o gateway precisava assumir e fazia o gateway consultar esse campo pra tomar a decisão.
Agora eu faço diferente. Eu não preciso criar um campo só pra guardar uma informação que eu vou usar só uma vez. Eu crio um script de evento workflow e dou um nome pra função. Custei a descobrir que eu posso fazer dessa forma 
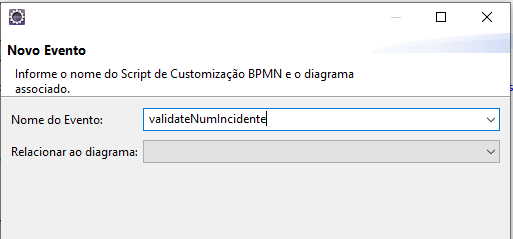
Essa função retorna true ou false. E no gateway eu só chamo a função e decido o caminho a ser tomado.
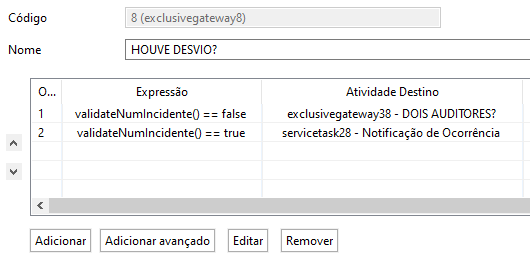
Espero ter ajudado.
8 curtidas
Nossa cara, também não imaginava que seria possível isso. Acho que isso claramente vai expressar o que eu quero fazer. Eu aprendi recentemente que posso fazer essa modularização mas nunca pensei que ela funcionava dentro do gateway.
1 curtida
Muito boa essa sua solução.
Já tinha usado esses eventos de processo em gateway, mas não dessa forma.
Muito bom!
Mais uma pra biblioteca de ideias 
1 curtida
@victorcastro
Essa era a minha resposta e era assim que fazíamos a maioria das funções de processo no by you ECM 3.0
TOP!
1 curtida
Genial cara, não imaginava que também dava pra fazer dessa forma. Agora não precisarei mais percorrer uma tabela Pai e Filho e guardar o total em um campo apenas para usar no gateway
1 curtida
Wikipedia, parceiro! Kkkkkkk mentira, autor: minha própria cabeça!
1 curtida
Eu descobri que dava pra fazer assim, de criar um arquivo compartilhado no processo, só porque fui estudar um processo que uma “filial” tinha isso nele.
Na documentação não tem falando isso e nos cursos (nem da academia fluig nem o presencial da totvs) sequer comentaram essa possibilidade.
2 curtidas
Pois é Bruno, eu sempre fico imaginando a quantidade de coisas que a gente não sabe, exatamente por não ter em lugar algum.
@Bruno_Gasparetto como é esse lance de “arquivo compartilhado”?
@Cassius , é um arquivo “compartilhado”, mas na verdade é mais pra ter uma função comum a todo um processo.
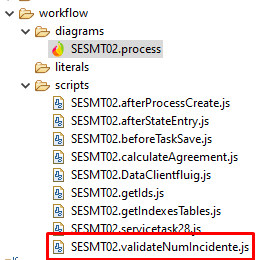
Se você olhar o post do VictorCastro vai ver no print que ele tem um processo chamado “SESMT02”. Aí ele criou um “evento” chamado validateNumIncidente pra esse processo.
O que o Eclipse/Fluig faz é criar um arquivo chamado SESMT02.validateNumIncidente.js e dentro desse arquivo tem a função validateNumIncidente.
Essa função você pode chamar em qualquer evento do processo e também utilizá-la numa expressão dentro dos Gateways BPM.
Então dá pra reaproveitar ao menos as funções dentro do mesmo processo.
2 curtidas
Existe um outro jeito de compartilhar funções entre processos, mas é um pouco menos elegante - armazená-las em datasets e fazer um eval() no resgate da função - nunca usei e me soa pouco prático…mas acredito que funcione perfeitamente!
O ideal era ter a possibilidade de ter um repositório comum no backend, não acham?
1 curtida
@daniel.cabral eu uso pacotes em forma de widgets com js dentro dele.
Fica comum a todos os formulários pelo menos.
2 curtidas
Victor, deste modo que você fez, poderia me explicar melhor por favor oque você escreveu de função? estou com este mesmo problema, mas estou com muita duvida sobre isso
Fala @joaopretti, beleza?
Então, a função basicamente executa um script e retorna TRUE ou FALSE. E na hora de colocar no gateway eu simplesmente testo o retorno dela: se validateNumIncidente() == false então vai pra um caminho. Se validateNumIncidente() == true vai pra outro.
Você pode fazer uma função retornar qualquer coisa, e na hora de configurar o gateway, definir o caminho de acordo com o que a função vai retornar.
Se ainda estiver com dúvidas, pode perguntar.
Estou fazendo desta maneira: